I was curious if I could scrape share information from the Toronto Stock Exchange website using Mechanize.
After quite a bit of regex, I was able to write a script to do so.
How it works
1) The script visits the search page. It then requests a “name starts with” search for each of the keywords A-Z and 0-9.
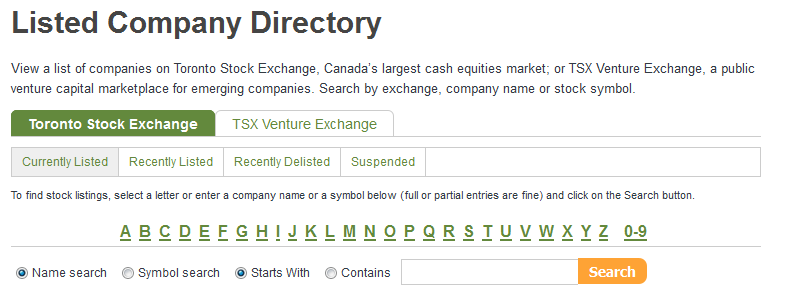
2) For every company returned in the results,
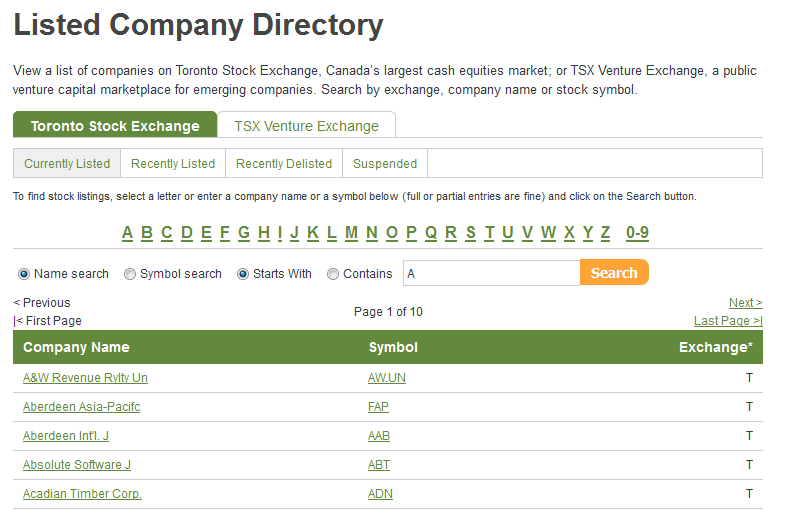
4) It visits the respective company’s page, and extracts the information desired. In this case I was interested in the company’s symbol, name, previous close, market cap, sector, industry, and description.
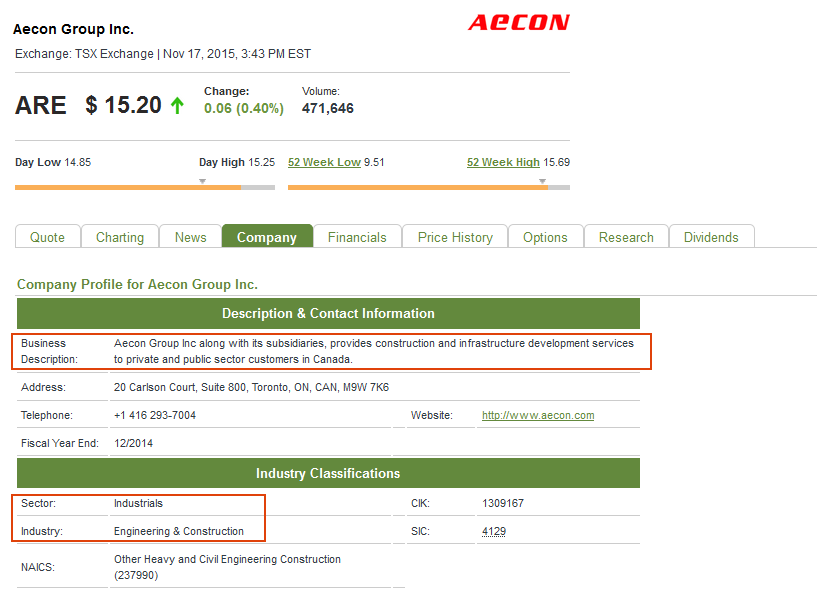
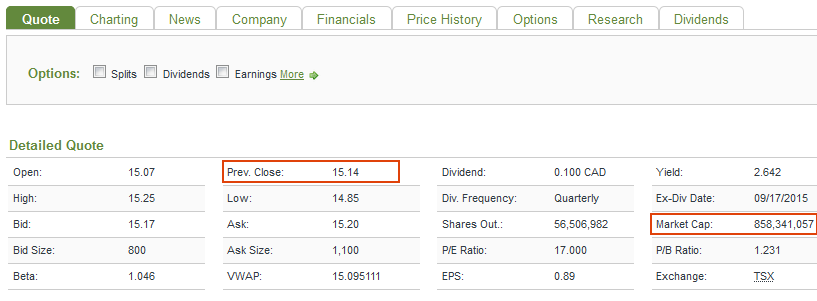
Here is the code,
#!/usr/bin/env ruby
require 'rubygems'
require 'mechanize'
require 'nokogiri'
require 'open-uri'
require 'csv'
#-------------
$agent = Mechanize.new
$alldem = []
$yell_it = false # show output in console
search_keywords = [ '0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L',
'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z' ]
partial_url = "http://www.tmxmoney.com/TMX/HttpController?GetPage=ListedCompanyDirectory&SearchCriteria=Name&SearchType=StartWith&SearchIsMarket=Yes&Market=T&Language=en&Page=1&SearchKeyword="
search_keywords.each do |kwd|
page = $agent.get( partial_url + kwd )
# ignores everything here (http://en.wikipedia.org/wiki/Ticker_symbol#Canada)
# such as .DB .PR ... with exception of .A .B
def getCompanyInfo (url)
### symbol, name, close, market_cap, sector, industry, description
# get page
page = $agent.get ( url )
# get symbol and name
combo = page.search(".qmCompanyName").text
symbol = /(?<=\()[A-Z]+(?=\))/.match(combo).to_s # ex. Bank of Nova Scotia (The) (BNS)
name = /.+(?=\s\([A-Z]+\))/.match(combo).to_s.gsub!(/\t/,'')
if symbol === ''
symbol = /(?<=\()[A-Z]+\.A(?=\))/.match(combo).to_s # ex. Brookfield Asset Management Inc. (BAM.A)
name = /.+(?=\s\([A-Z]+\.A\))/.match(combo).to_s.gsub!(/\t/,'')
if symbol === ''
symbol = /(?<=\()[A-Z]+\.B(?=\))/.match(combo).to_s # ex. Shaw Communications Inc. (SJR.B)
name = /.+(?=\s\([A-Z]+\.B\))/.match(combo).to_s.gsub!(/\t/,'')
end
elsif symbol === "PJC" # Jean Coutu Group (PJC) Inc. (The) ....
symbol = "PJC.A"
name = "Jean Coutu Group"
end
if ($yell_it) then puts( symbol, name) end
# get close
close = page.search(".qm-last-date .last span").text.to_f
if ($yell_it) then puts close end
# get sector, industry, and description
sector = '' , industry = '', description = ''
meh = page.search("td.label")
meh2 = page.search("td.data")
meh.each_with_index do | l, i |
if l.text.include? "Description"
description = meh2[i].text
elsif "Sector:" === l.text
sector = meh2[i].text
elsif "Industry:" === l.text
industry = meh2[i].text
end
end
if ($yell_it) then puts( sector, industry, description ) end
# get market_cap
market_cap = ''
partial_url = "http://web.tmxmoney.com/quote.php?qm_symbol="
page = $agent.get ( partial_url + symbol )
meh = page.search("td.label")
meh2 = page.search("td.data")
meh.each_with_index do | l, i |
if "Market Cap:" === l.text
market_cap = meh2[i].text.gsub!(',','').to_i
end
end
if ($yell_it) then puts market_cap end
# append all
if symbol != ''
$alldem.push( [symbol, name, close, market_cap, sector, industry, description] )
end
end
#-- Current page
company_links = page.search(".symbolGroup a")
# h = company_links[2]["href"]
company_links.each do |a|
getCompanyInfo( a["href"])
end
#-- Go through all the pages returned
while page.link_with(:text => /Next/)
page = $agent.click( page.link_with(:text => /Next/) )
company_links = page.search(".symbolGroup a")
company_links.each do |a|
getCompanyInfo( a["href"])
end
end
end
# CSV with all the data
CSV.open("le_listings.csv", "wb" ) do |csv|
csv << ['symbol', 'name', 'close', 'market_cap', 'sector', 'industry', 'description']
# csv << [symbol, name, close, market_cap, sector, industry, description]
# csv << $alldem[0]
for row in $alldem
begin
csv << row
rescue
row[6] = row[6].force_encoding('iso-8859-1').encode('utf-8') #stackoverflow.com/a/7048129 #http://po-ru.com/diary/fixing-invalid-utf-8-in-ruby-revisited/
csv << row
end
end
end
And the extracted data (for October 30, 2014) in CSV format →
References:
Update (November 2015):
Screenshots added for clarity of what script does.